Previous database design focused on tight control of schemas, but this hasn’t kept up with how databases are currently being used. The four V’s of database systems are Volume, Velocity, Variety and Veracity.
1. What is the problem?
Modern databases are still designed around old paradigms even through the underlying architecture has improved. Components of a DBMS are so interchangeable that they can be constructed for any specialization. While the DMBS has become very standardized, there is still no way of understanding the variety of the data – such as what the data is that is in the database and how it is being used. Adding this insight adds a big metadata component to a big data system.
2. Why is it important?
Data management involves tracking data in terms of who uses it and what is done with it. In secure environments, audit and control is a priority. Without these considerations, big data systems are ephemeral in the sense that the content is treated as non-crucial. As data is becoming more and more of an asset, it needs to be treated as such with the same level of rigor and support.
3. Why is it hard?
Storage economics is the biggest concern with Big MetaData. It only needs to be comprehensive enough to capture the full context of the data. The authors cite Application, Behavior, and Change (ABC) as the context paradigms to consider and balance in terms of the design space. Application context is the raw format of the information. Behavior context is how data is created and used – as well as the analytical results. Change context is the way that the data’s history is maintained. Within each context, there are diverse use cases to consider.
4. Why existing solutions do not work?
The Ground project is the first of its kind. This product provides technical and organizational awareness that is not typical of a DBMS. Ground offers many innovative concepts such as code version history associated to data version history – as well as a knowledge of who is accessing the data. As this paper generally discusses the Ground product, and highlights its innovations, it can be simply stated that no other solution offers this capabilities suite.
5. What is the core intuition for the solution?
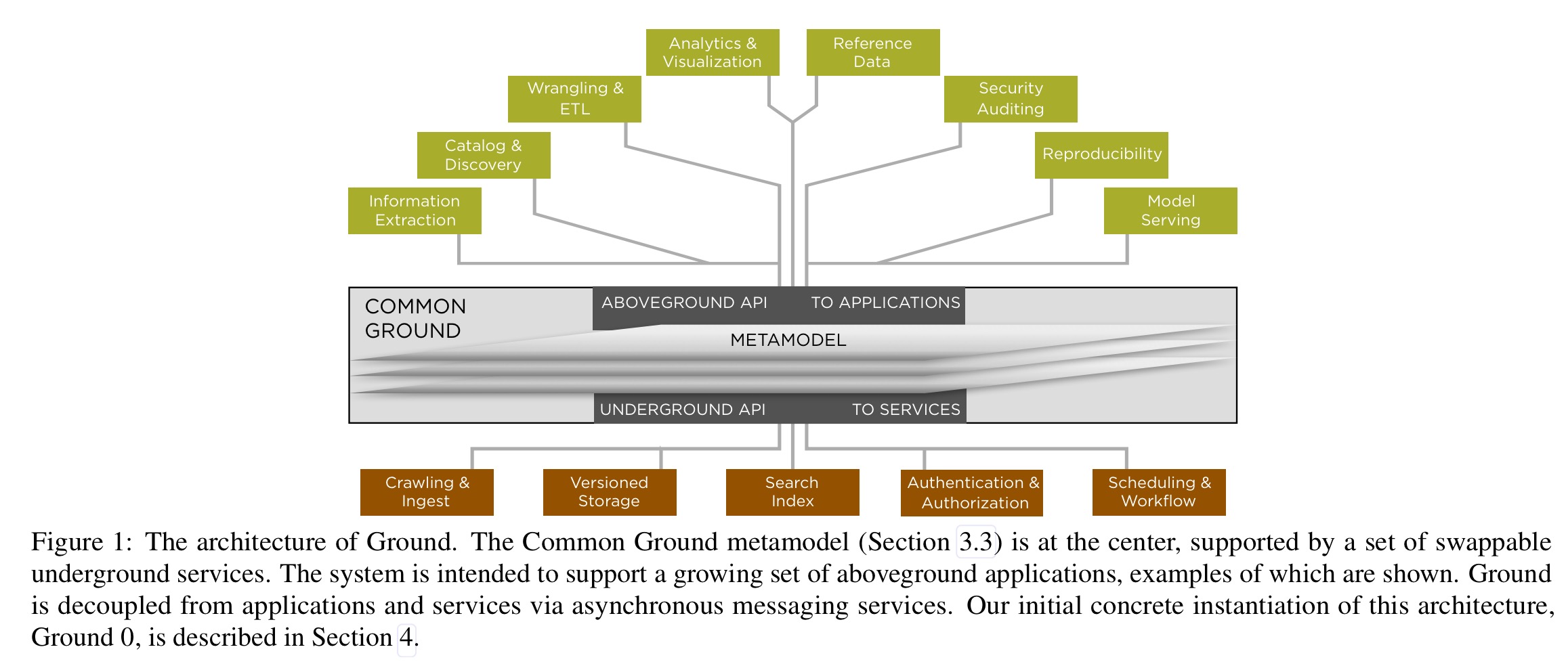
The authors define four central design requirements: Model Agnostic, Immutable, Scalable, and Politically Neutral. Model agnostic means that the context service does not change as the data model evolves. Immutable means that updating stored context retains a history of previous records. Scalable means that the data context can grow with the data and the data use. Politically Neutral means that customers will not be locked in to the data service. While meeting these requirements, Ground has both an external API for external applications and an internal API for swappable components.
6. Does the paper prove its claims?
This is a design paper – and so the design is discussed from the foundational model version component. The skeletons of classes extending version are presented in both is-a and has-a relationships. Additionally, illustrations are used to depict the model. The authors have put full code samples in GitHub for review. The authors discussion version graphs in terms of edges and nodes. Superversions are an innovation that compresses a series of version nodes and their common adjacencies – a superversion is a range of nodes. The authors describe how this support data lineage – which is relationships between versions.
7. What is the setup of analysis/experiments? is it sufficient?
All benchmarks were run on a single Amazon EC2 m4.xlarge machine with 4 CPUs and 16GB of RAM. This is an adequate test environment as it is similar to what many companies run in production. The initial dwell time and impact analysis time was recorded. The impact analysis was a recursive query using a User Defined Function. The dwell time analysis retrieved all session corresponding to a single server version.
Performance across systems varied significantly. This may be because steady state performance was not analyzed, but initial performance was.
8. Are there any gaps in the logic/proof?
While the authors ran the impact experiment with 5000 randomly chosen files, they did not run the experiment more than once. They should have varied the order in which the files were accessed and provided a box plot with the average latency. Also, increasing the average latency by almost a second with Postgres is almost unacceptable, as most queries return in less than a second. The same goes for the dwell time of TitanDB. It is an order of magnitude greater.
It was not clear that the tested systems were tuned equally. This may have caused variability in the results - and the order of magnitude difference in some cases.
9. Describe at least one possible next step.
The focus of this paper was in support of internal teams collaborating on data. The other use for data is as a back-end for an application. As more applications are lazily stored in data lakes also, it would be a use case for the discussed metadata. On possible use (with slight modification) may be to provide somewhat of a container for application session users. This can be done through the immutable attribute of Ground's design.
BibTex Citation
@inproceedings{hellerstein2017ground,
title={Ground: A Data Context Service.},
author={Hellerstein, Joseph M and Sreekanti, Vikram and Gonzalez, Joseph E and Dalton, James and Dey, Akon and Nag, Sreyashi and Ramachandran, Krishna and Arora, Sudhanshu and Bhattacharyya, Arka and Das, Shirshanka and others}
}