Consistency in distributed systems is a complex but crucial topic. Real-world systems like Facebook's Memcache implement a variety of techniques to balance consistency, availability, and performance. Meanwhile, researchers continue to develop new models like Causal+ to push the boundaries of what is possible in globally distributed services.
The Challenge
Imagine you are scrolling through your social media feed. Your friend Bob posts "Sally's sick" and then immediately follows up with "Sally's well." You see both updates and reply "Great news!" However, your friend Carol only sees Bob's first update and your reply, leaving her utterly confused. This scenario illustrates the challenges of maintaining consistency in distributed systems.
Consistency Models:
Consistency models provide guarantees about how updates to distributed state are propagated and become visible to users.
- Strong Consistency: Guarantees that all participants see updates in the same real-time order. It is the gold standard but can be challenging to implement in distributed systems.
- Sequential Consistency: Ensures a single ordering of all writes, but not necessarily matching real-time order.
- Causal Consistency: Enforces ordering only for causally related operations.
- Eventual Consistency: Guarantees that all updates will eventually become visible, but allows for temporary inconsistencies.
These models represent a trade-off between consistency and availability. Generally, weaker consistency models offer greater availability and performance.
From Theory to Practice: Facebook's Memcache
Facebook's Memcache system serves as a distributed in-memory cache for Facebook's massive data stores. Here are some key design decisions:
- Look-aside Cache: Clients explicitly check the cache before querying the database, simplifying the cache design.
- Non-authoritative Cache: The database remains the source of truth, allowing for simpler cache management.
- Lease Mechanism: Prevents inconsistencies due to concurrent or out-of-order updates.
- Invalidation-based Consistency: When data is modified in the database, invalidations are pushed to Memcache instances.
- Geo-distributed Design: Replicates data across multiple data centers, with specific protocols for cross-datacenter updates.
Beyond Traditional Models: Causal+ Consistency
Researchers are continually developing new consistency models to better serve the needs of modern distributed applications. One such model is Causal+ consistency, introduced in the paper "Don't Settle for Eventual: Scalable Causal Consistency for Wide-Area Storage with COPS."
Causal+ builds upon causal consistency by tracking dependencies between operations. When updates are replicated across data centers, the system ensures that all dependencies are satisfied before making the update visible. This approach provides stronger guarantees than eventual consistency while maintaining high availability and performance.
Memcached Goals and Design
Goal of Memcached: Memcached serves as an in-memory caching solution to reduce load on backend databases and services by caching frequently accessed data. This helps improve performance and scalability for read-heavy workloads like those of Facebook, where users consume an order of magnitude more content than they create.
"Lookaside" Cache Design: Memcached uses a "look-aside" cache design where:
- The cache sits alongside (not in front of) the database
- Clients explicitly ask the cache for data first using a simple get(key) operation
- On cache miss, clients explicitly fetch data from the database
- Clients are responsible for populating the cache with a set operation after fetching from the database
- Database updates are performed first, then the corresponding cache entries are deleted (not updated)
Rationale for this Design Choice: This design was chosen to:
- Keep the Memcached implementation simple and efficient
- Separate the caching tier from the storage tier, allowing each to be scaled independently
- Allow different guarantees for different tiers (caching vs. storage)
- Make Memcached non-authoritative, so the database remains the source of truth
- Simplify cache invalidation via idempotent deletes instead of complex updates
Leases and Problems Addressed
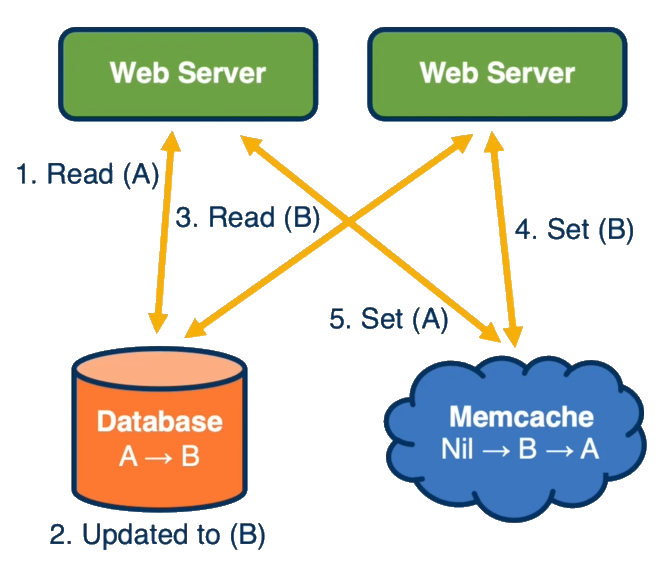
Leases Problem: One problem addressed by leases is the "stale set" problem, which can occur when:
- Multiple web servers simultaneously try to access a key that is not in the cache
- Each gets a cache miss and retrieves data from the database
- Between these requests, the database value changes
- The web servers' set operations arrive out of order, potentially leaving incorrect/stale data in the cache
Would this occur in a non-lookaside cache?: In a traditional front-of-database cache, this specific problem would not occur because the cache would be automatically updated as part of the data request pipeline. The cache would be responsible for fetching from the database in a coordinated way.
Would leases still be appropriate?: No, leases might not be appropriate or necessary in a non-lookaside design. A traditional front-of-database cache would typically use different consistency mechanisms since it would be authoritative and directly handle cache coherence.
Client-Side Functionality
Memcached relies on clients for several key operations:
- Request Routing: Clients determine which memcached server to contact based on consistent hashing of keys
- Serialization/Compression: Clients handle serializing objects and optionally compressing them
- Error Handling: Clients treat errors as cache misses and may skip inserting entries to avoid overloading
- Flow Control: Clients implement sliding window mechanisms to prevent incast congestion
- Cache Population: Clients are responsible for populating the cache after database reads
- Cache Invalidation: Clients must delete cache entries when database updates occur
Benefits of client-side processing:
- Keeps Memcached servers simple and efficient (focused on storage)
- Allows rapid iteration on client library without changing servers
- Reduces server-side bottlenecks for better scalability
- Prevents complex server coordination that would harm performance
Scaling Memcached
Scaling to Multiple Clusters:
- Memcached is scaled to multiple frontend clusters within the same datacenter
- Each cluster has its complete set of Memcached servers
- This creates multiple failure domains (a failure in one cluster does not impact others)
- Allows scaling to accommodate more requests to hot content
- Requires invalidations to be centralized to ensure ordering guarantees across clusters
Scaling Across Geo-distributed Datacenters:
- Each datacenter has its own Memcached clusters
- Data is replicated at the storage layer (databases) across datacenters
- Each datacenter's Memcached is populated independently by local clients
- Cross-datacenter traffic is minimized to handle high latency and limited bandwidth
- Changes in one datacenter are propagated via database replication, then reflected in other datacenters' caches
Invalidations and Remote Markers
Why Invalidations Are Used in Multi-cluster/Geo-distributed Setups:
- In a single cluster, when a client updates the database, it can directly delete the corresponding cache entry in the local Memcached servers
- In multi-cluster setups, invalidations must be broadcasted across clusters to maintain consistency
- In geo-distributed setups, a more complex mechanism is needed due to replication lag
Remote Markers in Geo-distributed Setup:
- Remote markers indicate that data in a local replica database may be stale
- When updating from a non-master region, a client: (1) sets a remote marker in the region, (2) performs the write to the master, and (3) deletes the key in the local cluster
- On subsequent requests, if a remote marker exists, queries are directed to the master region
- This helps minimize the probability of reading stale data due to replication lag
COPS and Consistency Issues
Read/Write Ordering Problem with Memcached:
- Memcached provides no ordering guarantees between keys
- This can lead to scenarios where clients observe updates in an order that violates causality
- Example: A user might see a reference to a photo before the photo itself is visible, or see an album with "friends only" ACL but with public content
COPS Solution:
- COPS (Clusters of Order-Preserving Servers) provides causal+ consistency
- It explicitly tracks causal dependencies between writes
- It ensures writes are committed only after their dependencies are satisfied
- Dependencies are checked before exposing writes to clients
- COPS-GT adds "get transactions" to obtain a consistent view of multiple keys
Causal+ vs Causal Consistency:
- Causal consistency ensures that operations respect causality relationships (if A happened before B causally, all clients observe A before B)
- Causal+ consistency adds convergent conflict handling on top of causal consistency
- Convergent conflict handling ensures that replicas never permanently diverge and conflicting updates to the same key are handled identically at all sites
- This combination ensures clients see a causally-correct, conflict-free, and always-progressing data store
The key innovation in COPS is providing scalable causal+ consistency where dependencies can span multiple servers in a datacenter, rather than requiring all dependent data to fit on a single machine as in previous systems.
Key Concepts
Distributed Systems These are systems where components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another. Examples include social media platforms, cloud storage services, and global financial systems.
Consistency In the context of distributed systems, consistency refers to how and when updates to the system's data become visible to different parts of the system. It's about ensuring that all nodes or users see the same data at the same time, or in a defined order.
Consistency Models These are formal guarantees about the ordering and visibility of updates in a distributed system:
- Strong Consistency: Guarantees that all participants see updates in the same real-time order.
- Sequential Consistency: Ensures a single ordering of all writes, but not necessarily matching real-time order.
- Causal Consistency: Enforces ordering only for causally related operations.
- Eventual Consistency: Guarantees that all updates will eventually become visible, but allows for temporary inconsistencies.
Availability This refers to the system's ability to remain operational and accessible, even in the face of failures or network partitions. There's often a trade-off between strong consistency and high availability.
Key-Value Stores A type of data storage system where data is stored as key-value pairs. It's often used in distributed systems for its simplicity and scalability.
Facebook's Memcache A distributed memory caching system used by Facebook to improve the performance of their data stores. Key concepts related to Memcache include:
- Look-aside Cache: A caching strategy where clients explicitly check the cache before querying the main database.
- Non-authoritative Cache: The cache is not the source of truth; the main database is.
- Lease Mechanism: A technique to prevent inconsistencies due to concurrent or out-of-order updates.
- Invalidation-based Consistency: When data is modified in the database, the corresponding cache entries are invalidated.
Geo-distribution The practice of distributing system components across multiple geographic locations or data centers. This improves performance for users in different regions but introduces challenges for maintaining consistency.
Causal+ Consistency A consistency model that builds upon causal consistency by tracking dependencies between operations. It aims to provide stronger guarantees than eventual consistency while maintaining high availability.
Replication The process of storing the same data on multiple machines or in multiple data centers. This is crucial for fault tolerance and improved performance in distributed systems.
Scalability The ability of a system to handle growing amounts of work by adding resources to the system. Distributed systems are often designed with scalability in mind.
Review Questions
What is the goal of Memcached? What does it mean that it's "lookaside" cache? Why did its creators choose this design point?
The goal of Memcached is to serve as an in-memory distributed caching system that reduces load on backend databases by caching frequently accessed data. As a "lookaside" cache, Memcached sits alongside (not in front of) the database, where clients explicitly check the cache first using get operations, and upon a cache miss, they directly fetch data from the database and then populate the cache themselves. Facebook's engineers chose this design to maintain simplicity in the Memcached tier, separate concerns between caching and storage, and allow independent scaling of each layer (ref). This design makes Memcached non-authoritative (the database remains the source of truth) and simplifies cache invalidation through idempotent deletes rather than complex update operations.
What is one Memcached problem addressed via Leases? Would this problem have occurred if this were not a "lookaside" cache, and, if so, would Leases still be an appropriate solution?
Memcached uses leases to address the "stale set" problem, which occurs when multiple web servers simultaneously experience cache misses, retrieve data from the database, but between these requests the database value changes. Without leases, their subsequent set operations may arrive out of order, potentially leaving stale data in the cache. If Memcached were not a lookaside cache but instead a traditional front-of-database cache, this specific problem would not occur because the cache would coordinate database access and manage cache coherence directly. Leases would likely be unnecessary in that design, as other consistency mechanisms would typically be employed.
Memcached relies on client-side functionality for several operations. What are those and why is client-side processing useful?
Memcached relies on client-side functionality for key operations including: request routing using consistent hashing, serialization and compression of data, error handling, flow control via sliding window mechanisms to prevent incast congestion, cache population after database reads, and cache invalidation when database updates occur. Client-side processing is useful because it keeps Memcached servers simple and focused solely on storage, enables rapid iteration on client libraries without changing server code, distributes computational load across clients rather than concentrating it on servers, and avoids complex server coordination that would harm performance and scalability.
How is Memcached scaled to multiple clusters?
Memcached is scaled to multiple clusters by creating separate frontend clusters within the same datacenter, each with its own complete set of Memcached servers. This approach creates multiple independent failure domains, improves fault tolerance, allows horizontal scaling to handle more requests to hot content by having the same content cached in multiple places, and enables better network configuration management. To maintain consistency across clusters, Facebook implemented a centralized invalidation system where updates trigger invalidations that are broadcast to all clusters, ensuring that stale data is not served.
What about across geo-distributed datacenters?
Across geo-distributed datacenters, each location maintains its own complete Memcached infrastructure with local clusters. Data is replicated at the storage layer with databases replicated across locations, rather than trying to maintain a single sharded cluster spanning multiple geographic locations. This design minimizes cross-datacenter traffic, which would be impractical due to high latency and limited bandwidth. Updates made in one datacenter are propagated to others through database replication, and Memcached servers in each datacenter are populated independently by local clients. To handle replication lag issues, special mechanisms like remote markers are employed to prevent serving stale data.
Why are invalidations or markers used in the multi-cluster or geo-distributed configurations but not in the single cluster design?
In a single cluster design, when a client updates the database, it can directly delete the corresponding cache entry in the local Memcached servers, ensuring consistency through this simple mechanism. However, in multi-cluster setups, invalidations must be broadcast across all clusters to maintain consistency since clients in different clusters might be accessing the same cached data. For geo-distributed configurations, remote markers are used to handle the additional complexity of replication lag between datacenters. These markers help track when data in a local replica database might be stale, directing queries to the master region when necessary, which is not a concern in the single-cluster scenario where all operations happen within the same datacenter.
What is the problem with the read/write ordering guaranteed by a system like Memcached that is addressed with the COPS work?
The fundamental problem with Memcached's consistency model is that it provides no ordering guarantees between different keys, which can lead to scenarios where clients observe updates in an order that violates causality. For example, a user might see a reference to a photo before the photo itself is available, or access an album with updated privacy settings but still see the previous content. These inconsistencies arise because Memcached treats each key independently with no awareness of relationships between different pieces of data, requiring complex application logic to handle potential inconsistencies.
How does the COPS solution solve this problem? What is Causal+ consistency/how is this different than just Causal?
COPS (Clusters of Order-Preserving Servers) solves the ordering problem by explicitly tracking and enforcing causal dependencies between writes. It ensures that data is replicated between clusters in a causally consistent order by having each write carry its dependencies and verifying that those dependencies are satisfied before committing the write. The system scales by tracking dependencies across an entire cluster, not just on a single server.
Causal+ consistency extends basic causal consistency by adding convergent conflict handling. While causal consistency ensures operations respect causality relationships (if A happened before B causally, all clients see A before B), causal+ additionally ensures that replicas never permanently diverge and that conflicting updates to the same key are resolved identically at all sites. This combination provides clients with a data store that is causally correct, conflict-free, and always shows progressive versions of keys, making it substantially easier for programmers to reason about distributed state.