Designing communication systems for distributed environments requires careful consideration of various factors:
- Scale of the system
- Heterogeneity of nodes
- Frequency of changes (e.g., node failures, mobility)
- Communication patterns
- Cost of different types of communications
Understanding these factors and the available design options leads to the creation of distributed systems that are efficient, scalable, and robust in the face of real-world challenges.
Mapping Application to Network Level
At the core of distributed system communication is the need to map application-level identifiers to network-level addresses. This mapping is crucial for routing messages between different nodes in the system. While this might seem straightforward in a small, controlled environment like a data center, it becomes increasingly complex as systems scale and span across wide-area networks.
Peer-to-Peer Systems: Decentralized Communication
Peer-to-peer (P2P) systems present an interesting case study in distributed communication. These systems, popularized by file-sharing applications like Napster and BitTorrent, operate without a central authority. Instead, they rely on various methods to locate and communicate with peers:
- Centralized Registry: Used by early systems like Napster, this approach provides quick lookups but introduces a single point of failure.
- Flooding/Gossip Protocols: Systems like Gnutella use this method, where requests are broadcast to all peers. While decentralized, it can be inefficient for large networks.
- Distributed Hash Tables (DHTs): A popular approach used by systems like Chord and Kademlia. DHTs provide a decentralized index that balances efficiency and scalability.
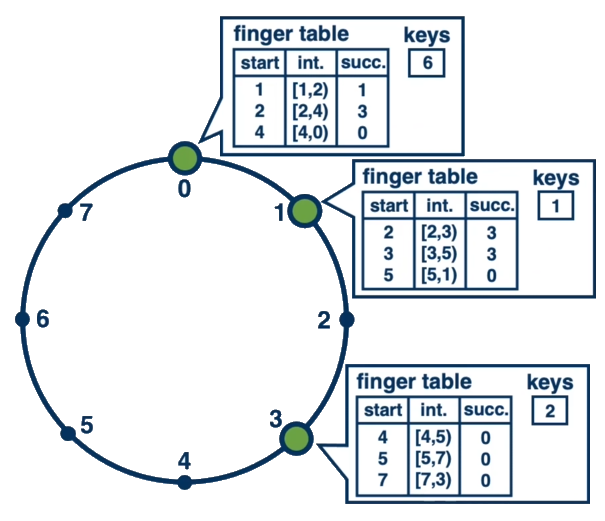
Chord: A Closer Look at DHTs
Chord (ref), a pioneering DHT-based P2P system, offers insights into how these systems work:
- It uses a ring topology to organize peers and data.
- Keys and peer IDs are mapped to the same identifier space using a hash function.
- "Finger tables" are maintained to speed up lookups, typically achieving O(log N) time complexity.
- The system dynamically adjusts as peers join or leave the network.
Hierarchical Designs: Balancing Efficiency and Scalability
While P2P systems offer great scalability, many real-world scenarios benefit from hierarchical designs. These designs recognize that not all nodes in a system are equal, and communication patterns often have locality.
Consider mobile networks as an example:
- Base stations form a high-speed, wired backbone network.
- Mobile devices connect to base stations via wireless links.
- This two-tiered approach allows for efficient routing and management of mobile nodes.
The Mobile Network Challenge
Mobile networks present unique challenges due to the movement of devices. Two key approaches for handling this mobility are:
- Lazy Update: Mobile devices only update their location when they need to communicate. This reduces update traffic but can lead to longer lookup times.
- Eager Update: Devices update their location whenever they move. This ensures faster lookups but generates more update traffic.
The choice between these approaches depends on factors like the relative cost of wired vs. wireless communication and the frequency of movement vs. communication.
Key Concepts
Distributed Systems: Computer systems composed of multiple nodes that communicate and coordinate their actions by passing messages to achieve a common goal.
Application-level identifiers: Names or labels used within an application to identify resources or nodes, which need to be translated to network addresses for communication.
Network-level addresses: Unique identifiers (like IP addresses) used to locate and communicate with specific nodes in a network.
Peer-to-peer (P2P) systems: Decentralized systems where all nodes (peers) have equal status and can communicate directly with each other without a central server.
Centralized Registry: A central server that maintains information about all peers in a P2P system, used for lookups but potentially creating a single point of failure.
Flooding/Gossip Protocols: Communication methods where information is broadcast to all or many nodes in a network, potentially reaching the intended recipient but at the cost of network efficiency.
Distributed Hash Tables (DHTs): Data structures used in P2P systems to efficiently locate resources without relying on a central coordinator.
Chord: A specific implementation of a DHT-based P2P system, using a ring topology and finger tables for efficient lookups.
Hash function: An algorithm that maps data of arbitrary size to fixed-size values, used in DHTs to assign identifiers to both data and nodes.
Finger tables: In Chord, data structures maintained by each node to speed up lookups by storing information about other nodes at exponentially increasing distances around the identifier ring.
Hierarchical designs: Network architectures that organize nodes into different levels or tiers, often to balance efficiency and scalability.
Mobile networks: Communication systems designed to support devices that can change their physical location while maintaining network connectivity.
Base stations: Fixed points in a mobile network that provide wireless connectivity to mobile devices and connect to the wired backbone network.
Lazy update: An approach in mobile networks where devices only update their location information when they need to communicate.
Eager update: An approach in mobile networks where devices update their location information whenever they move to a new area.
Review Questions
What is the goal of Peer-to-Peer systems? What are some fundamental differences with other types of distributed systems: e.g., considering a single datacenter, or even a set of datacenters as what was described in the Spanner and other systems?
The goal of Peer-to-Peer (P2P) systems is to provide a decentralized architecture where nodes collaborate as equals without centralized control or hierarchical organization. P2P systems aim to efficiently locate and distribute data items across participant nodes in a scalable, fault-tolerant manner.
Fundamental differences from datacenter-based distributed systems include:
-
Decentralization: P2P systems operate without central coordination or authority, while datacenter systems typically have centralized management. In P2P, all nodes are functionally equivalent.
-
Scale and geographical distribution: P2P systems are designed to operate across the wide area network with potentially millions of nodes across different administrative domains, whereas datacenter systems are typically more controlled environments with known participants.
-
Dynamism: P2P systems are built to handle frequent node arrivals and departures (churn) as a normal condition, while datacenter systems often treat failures as exceptional.
-
Trust assumptions: P2P systems must operate in environments where nodes may not necessarily trust each other, while datacenter systems often assume trusted components.
-
Network assumptions: P2P systems typically only assume basic IP connectivity, while datacenter systems can leverage specialized hardware and interconnect capabilities like RDMA, atomic operations, and optimized collective operations.
What are the tradeoffs with possible strategies to find the appropriate peer in a P2P system?
The papers discuss several strategies for locating peers in P2P systems, each with different tradeoffs:
-
Centralized Registry:
- Advantages: Simple, fast lookup (single round-trip time)
- Disadvantages: Single point of failure, limited scalability, requires central trust
- Example: Napster used this approach
-
Flooding/Gossip-based protocols:
- Advantages: Fully decentralized, no need for central authority
- Disadvantages: High message overhead, unbounded search time, network congestion
- Example: Gnutella used this approach
-
Distributed Hash Tables (DHTs):
- Advantages: Decentralized, predictable lookup times (typically O(log N)), balanced load
- Disadvantages: More complex to implement and maintain, requires structure
- Examples: Chord, Pastry, Tapestry, Kademlia (a distributed hash table (DHT) used in peer-to-peer (P2P) networks to locate and retrieve data from other nodes)
The key tradeoffs involve the balance between:
- Lookup efficiency (number of messages and latency)
- Scalability (ability to handle large numbers of nodes)
- Resilience to failures and churn
- Maintenance overhead
- Administrative decentralization
What's the basic goal and functionality of a DHT? What could be stored in the DHT elements? (i.e., What kind of information can be stored in a DHT in a P2P system?)
The basic goal of a Distributed Hash Table (DHT) is to provide an efficient, scalable, and decentralized lookup service that maps keys to nodes responsible for them in a distributed system.
Core functionality of a DHT:
- It assigns keys to nodes using a consistent hashing function
- It provides a way to efficiently locate the node responsible for any given key
- It automatically redistributes keys when nodes join or leave
- It maintains enough routing information to ensure bounded lookup time
Information that can be stored in DHT elements:
- The actual data values associated with keys
- Metadata about where the actual data is stored (common in P2P systems)
- References/pointers to resources (URLs, file locations, etc.)
- Service locations or network addresses
As noted in the Chord paper: "Chord provides support for just one operation: given a key, it maps the key onto a node. Data location can be easily implemented on top of Chord by associating a key with each data item, and storing the key/data item pair at the node to which the key maps."
The lecture mentions examples like cooperative mirroring of software distributions, time-shared storage for intermittently connected nodes, distributed indexes for keyword search, and large-scale combinatorial search applications.
How does Chord operate? What is stored in the DHT? What happens when an element and data is added to Chord? What happens when a lookup is performed? What about when a node fails/is removed?
Chord operates by organizing nodes in a logical ring based on their identifiers:
Key components:
- Nodes and keys have m-bit identifiers from a circular identifier space (0 to 2^m-1)
- Keys are assigned to the first node whose ID equals or follows the key (its "successor")
- Each node maintains information about its successor in the ring
What is stored in the DHT:
- Chord itself only maintains the mapping of keys to nodes
- The actual data (or references to data) associated with keys is stored at the responsible nodes
- Each node maintains a finger table with routing information and a successor pointer
When an element/data is added:
- The key for the data is generated using a hash function like SHA-1
- The node responsible for the key is located through the lookup process
- The data (or a reference to it) is stored at that node
When a lookup is performed:
- If the key is local to the searching node, it returns the result immediately
- Otherwise, the node consults its finger table to find the closest preceding node
- The query is forwarded to that node, which repeats the process
- This continues until the node responsible for the key is reached
- The lookup takes O(log N) hops in a stable N-node network
When a node fails/is removed:
- Chord maintains successor lists (not just single successors) to handle failures
- If a node's successor fails, it uses the next entry in its successor list
- A stabilization protocol runs periodically to update successor pointers
- The finger tables are also periodically corrected using the fix_fingers routine
- When a node leaves properly, keys it was responsible for are transferred to its successor
- The join/leave protocols ensure that each key is always reachable by some node
What is the purpose of the fingers tables/what problem do they solve? What information do they store, how/when are they updated, how are they used?
Purpose of finger tables: Finger tables accelerate the lookup process in Chord by providing shortcuts around the ring. Without finger tables, lookups would require traversing the ring one node at a time, resulting in O(N) lookup time. With finger tables, lookups take O(log N) time.
Problems they solve:
- They dramatically reduce lookup time from linear to logarithmic complexity
- They distribute the routing information across nodes (no node needs complete information)
- They enable efficient adaptation to node joins and departures
Information stored in finger tables: Each node n maintains a finger table with up to m entries (where m is the number of bits in the identifier space). The ith entry contains:
- The identity of the first node s that succeeds n by at least 2^(i-1) on the identifier circle
- This node s is the successor of (n + 2^(i-1)) mod 2^m
- Each entry includes both the Chord identifier and the IP address (and port) of that node
How/when they are updated:
- When a node first joins, it initializes its finger table by querying other nodes
- The periodic fix_fingers() procedure (ref) updates finger table entries
- Each call to fix_fingers() updates a random finger table entry
- This ensures all entries are eventually corrected after changes in the network
- Nodes also update fingers when they learn about better routes during lookups
How they are used:
- During a lookup for key k, a node n first checks if k is between n and its successor
- If yes, the successor is the target node responsible for k
- If no, n searches its finger table for the closest preceding node j to k
- The query is then forwarded to j, which repeats the process
- Each step reduces the distance to the target by at least half, ensuring O(log N) hops
What are the problems that are addressed with hierarchical designs of distributed systems?
Hierarchical designs of distributed systems address several key problems:
-
Heterogeneity of nodes and connections: Hierarchical designs accommodate the differences between mobile hosts and fixed infrastructure, or between edge nodes and data center nodes. They recognize that nodes have different capabilities, power constraints, and connection qualities.
-
Scalability: By organizing nodes into hierarchical structures, the system can scale to much larger numbers of nodes while maintaining efficient communication patterns and bounded state at each node.
-
Locality and performance: Hierarchical designs exploit the physical and logical proximity of nodes to reduce communication costs and improve performance. They allow communication patterns to be optimized for different layers of the hierarchy.
-
Mobility management: In mobile networks, hierarchical designs help manage the location of mobile nodes efficiently. Base stations or mobile support stations (MSSs) can track mobile hosts within their cells, while higher-level components handle routing between cells.
-
Resource constraints: By pushing computation and communication responsibilities primarily to the fixed infrastructure, hierarchical designs can accommodate resource-constrained mobile hosts that have limited power, processing, and communication capabilities.
-
Administrative boundaries: Hierarchical designs can respect organizational or administrative boundaries while still enabling global connectivity and communication.
-
Dynamic changes: Hierarchical systems can isolate the effects of dynamic changes (like node mobility or failures) to specific parts of the hierarchy, reducing the overhead of maintaining global state.
What are the problems with using a DHT across all mobile nodes as peers for the basic SEARCH and INSERT operations in a mobile network?
Using a DHT directly across all mobile nodes in a mobile network presents several significant problems:
-
High search cost: Each message between mobile hosts would require finding the current location of the destination node, incurring a significant search overhead proportional to the number of nodes.
-
Excessive wireless communication: DHT operations would require multiple messages over power-intensive and bandwidth-limited wireless links, as both the sender and receiver would be mobile hosts.
-
Power consumption: Mobile hosts have limited battery power, and DHT operations would require them to frequently send and receive messages, rapidly depleting their energy reserves.
-
Disconnection and doze mode handling: Mobile hosts often disconnect or enter doze mode to conserve power, but traditional DHT algorithms expect continuous node availability, making the DHT unreliable.
-
Mobility disrupts logical structure: The DHT's logical structure (like Chord's ring) would need frequent reconfiguration as nodes move between cells, creating significant maintenance overhead.
-
Non-uniform resource distribution: Mobile hosts have vastly different capabilities from fixed infrastructure, but a pure P2P approach treats all nodes equally.
-
Inefficient network utilization: Communication between mobile hosts in different cells would unnecessarily traverse wireless links multiple times when it could be more efficiently routed through the fixed network.
The Badrinath paper (ref) suggests addressing these problems using a "two-tier principle" where:
- The fixed infrastructure (Mobile Support Stations) handles most of the DHT operations
- Mobile hosts only participate minimally, conserving their resources
- Location management strategies (search, inform, proxy) handle the mobility of nodes
- The logical structure is maintained among the fixed nodes, not the mobile hosts
This approach significantly reduces wireless communication, power consumption, and search overhead while accommodating the unique characteristics of mobile networks.