From high-speed interconnects and resource disaggregation to persistent memory and evolving software stacks, the landscape of data center computing is rapidly changing.
Many modern applications are powered by data center platforms and services. These data center-based services are distributed systems.
The End of Moore's Law and the Rise of Specialization
For decades, Moore's Law—the observation that transistor density doubles approximately every 18 months—has been a driving force in computing. As this trend is slowing down, the industry has shifted towards specialization to continue improving performance.
This specialization comes in various forms:
- Many-core systems and multi-threading: A direct response to the slowdown in single-core performance improvements.
- Specialized components: GPUs and TPUs for AI workloads, FPGAs for programmable circuits in network elements.
- New memory and storage technologies: Addressing data access and processing requirements.
High-Speed Interconnects and RDMA
One significant trend is the adoption of high-speed interconnect networks, such as InfiniBand, with Remote Direct Memory Access (RDMA) capabilities. RDMA allows for direct memory access from the memory of one computer into that of another without involving either computer's operating system. This technology enables:
- Higher bandwidth and lower latency compared to traditional Ethernet networks
- Reduced CPU load for network operations
- New possibilities for shared memory access across distinct physical nodes
Resource Heterogeneity and Disaggregation
Modern data centers are becoming increasingly heterogeneous, with a mix of different types of compute, memory, and storage resources. This heterogeneity, combined with changing workload requirements, has led to a trend towards resource disaggregation.
Disaggregation allows different types of resources (compute, memory, storage) to be independently added and scaled. This approach offers several benefits:
- Greater flexibility in resource allocation
- Improved utilization of hardware resources
- Ability to scale specific resource types independently
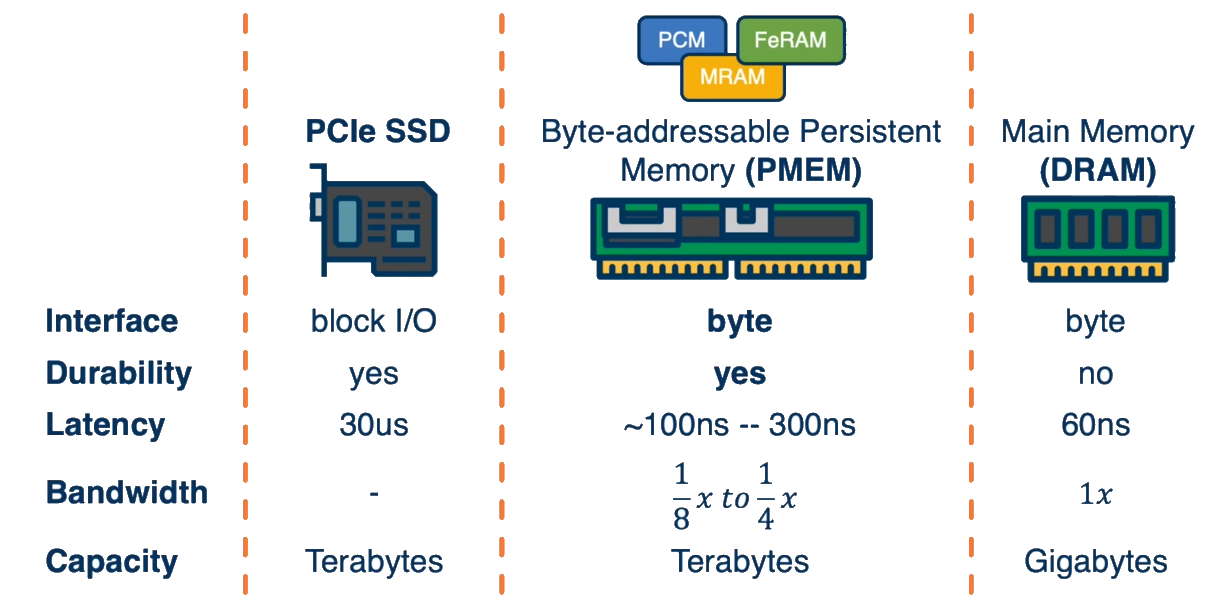
Persistent Memory: Bridging the Gap Between Memory and Storage
The emergence of persistent memory technologies, such as Intel's Optane, is blurring the traditional boundaries between memory and storage. These technologies offer:
- Byte-addressable access like DRAM
- Persistence like storage devices
- Performance closer to DRAM than traditional storage
- Larger capacity than typical DRAM configurations
This development has implications for system design, particularly in areas like data persistence and recovery.
The Evolution of Software Stacks
The software stack in data centers is also evolving. There is a shift from virtual machines to containers and microservices. This change affects how we package, distribute, and manage software components in cluster systems and data centers.
Key Concepts
Moore's Law The observation made by Gordon Moore, co-founder of Intel, that the number of transistors on a microchip doubles about every two years, while the cost halves. This trend has been a driving force in technological advances in the digital age.
Specialization In computing, specialization refers to the design of hardware or software components to perform specific tasks more efficiently than general-purpose components.
GPU (Graphics Processing Unit) A specialized processor originally designed to accelerate graphics rendering. Modern GPUs are used for a wide range of parallel processing tasks, particularly in machine learning and AI.
TPU (Tensor Processing Unit) A specialized AI accelerator application-specific integrated circuit (ASIC) developed by Google specifically for neural network machine learning.
FPGA (Field-Programmable Gate Array) An integrated circuit designed to be configured by a customer or a designer after manufacturing. FPGAs contain an array of programmable logic blocks and a hierarchy of reconfigurable interconnects.
RDMA (Remote Direct Memory Access) A direct memory access from the memory of one computer into that of another without involving either computer's operating system. RDMA allows high-throughput, low-latency networking.
InfiniBand A computer networking communications standard used in high-performance computing that features very high throughput and very low latency.
Resource Heterogeneity In data centers, this refers to the presence of diverse types of computing resources (e.g., CPUs, GPUs, FPGAs) and memory/storage technologies within the same system.
Resource Disaggregation An approach to data center architecture where different types of resources (compute, memory, storage) are separated into distinct pools that can be independently scaled and allocated as needed.
Persistent Memory A type of memory that combines the performance characteristics of DRAM with the persistence of storage devices. It retains its contents even when electrical power is removed.
Intel Optane A brand of persistent memory and solid-state drive products developed by Intel using 3D XPoint technology.
Virtual Machine A software emulation of a computer system, providing functionality of a physical computer. It allows multiple OS environments to co-exist on the same physical hardware.
Container A standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another.
Microservices An architectural style that structures an application as a collection of loosely coupled, independently deployable services.
Distributed System A system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another.
Data Center A facility composed of networked computers and storage that businesses or other organizations use to organize, process, store and disseminate large amounts of data.
Review Questions
What are some of the emerging technology trends in datacenters? What is motivating their adoption?
Several key technology trends are emerging in modern datacenters:
-
Hardware Resource Disaggregation: Breaking monolithic servers into independent, network-attached hardware components (CPU, memory, storage) that can be scaled independently. This is motivated by inefficient resource utilization, poor hardware elasticity, coarse-grained failure domains, and the need to better support hardware heterogeneity in monolithic servers.
-
High-speed Interconnect Networks: Technologies like InfiniBand with RDMA capabilities are becoming prevalent, providing much higher bandwidth and lower latency than traditional Ethernet.
-
Resource Heterogeneity: Increasing diversity of compute resources including specialized accelerators (GPUs, TPUs for AI workloads), programmable circuits (FPGAs), and programmable network elements (smart NICs).
-
Persistent Memory Technologies: New memory technologies like Intel's Optane DC Persistent Memory DIMMs provide durability with sub-microsecond latency, dramatically faster than traditional persistent storage.
-
Container-based Software Stacks: Evolution from virtual machines to containers to microservices for more flexible resource management.
These trends are motivated by limitations in the monolithic server model, including:
- Inefficient resource utilization (only ~50% utilization in production clusters)
- Poor hardware elasticity (difficult to add/remove components)
- Coarse failure domains (component failure affects entire server)
- Challenges in supporting hardware heterogeneity
What is RDMA, what are the benefits it provides?
RDMA (Remote Direct Memory Access) is a networking technology that allows direct memory access from the memory of one computer to the memory of another without involving either computer's operating system.
Benefits of RDMA:
- Bypass CPU: RDMA operations bypass the remote CPU, saving CPU cycles for other tasks
- Low Latency: Provides extremely low latency (1-2μs) for network operations
- High Bandwidth: Supports high bandwidth data transfers
- Low CPU Utilization: Minimal CPU overhead for network operations
- Zero-Copy Network Transfers: Data can move directly from application memory to the network and vice versa without intermediate copies
RDMA provides multiple transport types:
- Reliable Connected (RC): Provides one-sided RDMA operations (READ, WRITE, ATOMIC) and reliable data delivery
- Unreliable Connected (UC): Supports WRITE operations without guaranteed reliability
- Unreliable Datagram (UD): Connectionless transport that doesn't support one-sided operations but scales better to large clusters
The papers discuss two main forms of RDMA communication:
- One-sided RDMA: One endpoint directly accesses memory of another without remote CPU involvement
- Two-sided RDMA: Both endpoints are involved in communication, similar to traditional send/receive operations
Why and how does RDMA change how one could perform RPC among a client and server in a datacenter? What are, if any, the performance implications of such RPC designs compared to a traditional RPC implementation?
RDMA changes RPC implementation in several fundamental ways:
Traditional RPC Implementation:
- Requires OS involvement on both client and server
- Multiple data copies (application buffer → kernel → NIC → kernel → application)
- High CPU utilization for message processing
- Relatively high latency due to context switches and copying
RDMA-based RPC Approaches:
-
One-sided RDMA-based RPC: Client uses RDMA WRITEs to directly place requests in server memory and server responds similarly.
- Pros: Minimal CPU involvement, lower latency potential
- Cons: Not flexible for data structures, often requires multiple operations for data access
-
Two-sided RDMA-based RPC: Uses RDMA's messaging verbs (SEND/RECV) but with kernel bypass and zero-copy benefits.
- Pros: More flexible than one-sided, better aligned with RPC semantics
- Cons: Requires server CPU involvement
Performance implications:
- Latency: RDMA-based RPCs can achieve under 5μs latency compared to 10-100μs for traditional implementations
- Throughput: Can achieve millions of operations per second per server
- CPU Efficiency: Much lower CPU utilization per operation
- Scalability: Depends on transport type - connected transports (RC, UC) face scalability issues in large clusters, while datagram transport (UD) scales better
The FaSST paper specifically shows that for distributed transactional systems, two-sided unreliable datagram RPCs can outperform one-sided RDMA approaches when accounting for the real-world access patterns needed to work with data structures. While one-sided operations can be faster in microbenchmarks, accessing real data often requires multiple operations, tipping the performance balance toward two-sided RPCs.
What is non-volatile/persistent memory (NVM), what are the benefits it provides?
Non-volatile main memory (NVMM), also called persistent memory, refers to memory technologies that provide durability like storage but with performance closer to DRAM.
Key examples include Intel's Optane DC Persistent Memory Modules (Optane DIMMs), which attach to the CPU over the memory bus and provide byte-addressable access.
Benefits of NVMM:
- Performance: Sub-microsecond access latency (100-300ns), which is orders of magnitude faster than SSDs (10μs+) though still slower than DRAM
- Durability: Data persists after power loss
- Byte-addressability: Unlike block devices, can be accessed at byte granularity through loads and stores
- Higher Density and Lower Cost: Higher capacity and lower cost per GB than DRAM (e.g., for 128GB modules, ~$5/GB for Optane vs. ~$35/GB for DRAM)
- Direct CPU Access: Applications can directly access persistent storage through memory instructions
- Simplified Storage Stack: Eliminates much of the traditional storage stack complexity
NVMM significantly changes system design by making durability achievable at near-memory speeds, allowing for new programming models that blend storage and memory concepts.
Why and how does NVM change how one could implement RPC over Remote Direct Non-Volatile Memory Access?
NVM fundamentally changes remote memory access patterns because durability now requires less time than a network round trip. This reverses the historical trend where persistent storage was much slower than network communication.
Changes to RPC over Remote NVMM:
-
Durability Guarantees: With RDMA, making writes to remote NVMM durable requires additional operations:
- Simple RDMA writes don't guarantee durability - data might remain in NIC/PCIe buffers
- A follow-up RDMA read is needed to flush pending writes (creating "RDMA pwrites")
- Must disable DDIO (Data Direct I/O) at the server to ensure writes go directly to NVMM
-
Performance Considerations:
- The need for additional operations to ensure durability reduces the latency advantage of one-sided RDMA over RPCs
- For small persistent writes, RPCs have comparable latency to one-sided RDMA with durability guarantees
- For bulk writes, disabling DDIO counter-intuitively improves performance by avoiding random accesses to NVMM
-
CPU Cache Interactions:
- Current CPU caches aren't optimized for NVMM
- Cache eviction policies can cause unnecessary write amplification
- Repeated writes to the same location (e.g., counters in logs) perform poorly due to cache line invalidation
-
DMA Engine Utilization:
- On-CPU DMA engines can be leveraged to improve bulk write performance to NVMM
- Disabling Direct Cache Access (DCA) for DMA engines can improve throughput for large writes
As shown in the paper "Challenges and Solutions for Fast Remote Persistent Memory Access," the latency advantage of one-sided RDMA over RPCs is significantly reduced when durability is required. For small writes (64B), RDMA with persistence guarantees has 2.9μs latency vs. 2.3μs for RPCs - making RPCs a viable and sometimes better option for persistent memory workloads.
What is the goal of disaggregation? What are the technology assumptions that are required in order to make resource disaggregation possible?
The goal of hardware resource disaggregation is to break apart traditionally monolithic servers into independently scalable, network-attached hardware components. This aims to address several limitations of monolithic servers:
- Improve Resource Utilization: Enable more efficient packing of resources by allowing independent allocation of CPU, memory, and storage
- Increase Elasticity: Allow individual resource types to be added, removed, or scaled independently
- Enable Fine-grained Failure Handling: Isolate component failures to prevent them from affecting the entire system
- Support Hardware Heterogeneity: Make it easier to introduce new hardware technologies without replacing entire servers
- Allow Independent Scaling: Scale different resource types based on application needs
Technology assumptions required for resource disaggregation:
-
Fast Network Technologies: Network speed must be close enough to local interconnect speeds that the performance penalty of disaggregation is acceptable. Technologies like InfiniBand and emerging interconnects will soon reach 200-400Gbps, making them competitive with memory bus bandwidth.
-
Low-Latency Networking: Network latency must be low enough (1-2μs) to enable efficient remote resource access.
-
Network-Attached Components: Hardware components must have their own network interfaces or be directly accessible from the network.
-
Computational Power in Components: Non-processor hardware (memory, storage) needs sufficient local computational capabilities to manage themselves without relying on remote CPUs.
-
New System Software Architecture: Traditional operating systems built for monolithic servers must be redesigned for disaggregated hardware, which is the goal of the splitkernel architecture proposed in LegoOS.
LegoOS implements the splitkernel architecture where traditional OS functionality is split into loosely-coupled monitors that run directly on hardware components. These monitors communicate via network messaging, and the splitkernel handles global resource management and failure handling across distributed components.