Data centers form the backbone of the interconnected world. These massive facilities, housing thousands of servers, are responsible for powering everything from cloud services to artificial intelligence applications.
The Scale of Modern Data Centers
Modern data centers are a far cry from the server rooms of yesteryear. Today's hyperscalers like Google, Amazon, and Facebook operate facilities of staggering proportions:
- Thousands of server components
- Specialized hardware for various workloads (compute, storage, AI acceleration)
- Exponential growth in size and complexity
This scale presents unique challenges in resource allocation, workload management, and system reliability.
The Management Stack: More Than Just Hardware
Managing a data center involves far more than just keeping the lights on and the servers cool. It includes efficiently running diverse applications with varying requirements:
- Multi-tenancy: Running multiple applications, often for different customers, while ensuring isolation and resource fairness.
- Application diversity: Handling both long-running services and short-lived batch jobs.
- Performance objectives: Balancing latency-sensitive tasks with throughput-oriented workloads.
- Resource allocation: Matching tasks to appropriate hardware resources (CPU, memory, storage, specialized accelerators).
- Orchestration: Coordinating the deployment of interdependent tasks across the data center.
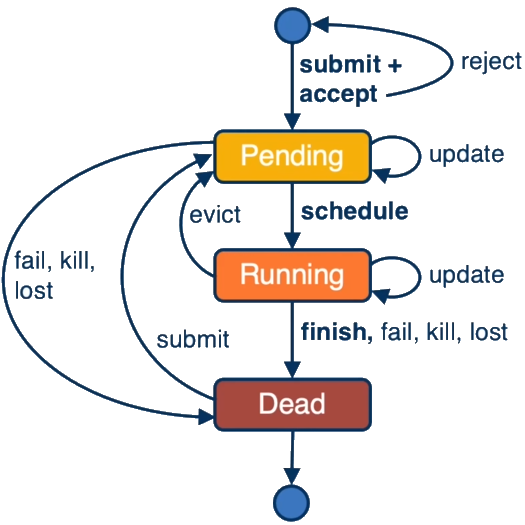
Borg: Google's Revolutionary Resource Manager
To tackle these challenges, Google developed Borg, a cluster management system that later inspired the widely-used Kubernetes platform. Borg's architecture provides valuable insights into effective data center management:
Key Components of Borg:
- Borg Master: The brain of the system, handling client requests and maintaining cell state.
- Scheduler: Determines task admission and resource allocation.
- Borglet: A local agent on each machine, managing task execution and resource monitoring.
Scalability and Reliability Features:
- Replication: The Borg Master is replicated for fault tolerance.
- Asynchronous design: Decoupling scheduling logic from actual resource allocation.
- Caching and equivalence classes: Optimizing scheduling decisions.
- Containerization: Isolating tasks and managing resource shares.
The Benefits of Resource Sharing
One of Borg's key innovations was its decision to share underlying resources between high-priority services and lower-priority batch jobs. This approach led to significant improvements in resource efficiency:
- 20-30% fewer machines required compared to segregated configurations
- Ability to reclaim resources dynamically from lower-priority tasks
Looking to the Future
As data centers continue to evolve, new challenges and opportunities emerge:
- Hardware heterogeneity: Adapting to diverse processing units and memory technologies.
- Disaggregation: Exploring new architectures that separate compute and storage resources.
- Energy efficiency: Optimizing for both performance and sustainability.
The lessons learned from systems like Borg will be crucial in developing the next generation of data center management tools, ensuring that the digital infrastructure can keep pace with the ever-growing demands of the connected world.
Key Concepts
Data Center: A facility housing a large number of computer servers and associated components, used for storing, processing, and distributing large amounts of data.
Hyperscalers: Large technology companies (like Google, Amazon, Facebook) that operate enormous data centers to provide cloud and internet services at a global scale.
Multi-tenancy: The practice of running multiple applications or serving multiple customers on the same infrastructure while maintaining isolation between them.
Service Level Objective (SLO): A target level of performance or resource allocation promised to an application or customer.
Service Level Agreement (SLA): A contract that specifies the consequences of meeting or violating SLOs.
Borg: Google's cluster management system, which forms the basis for Kubernetes.
Cell: In Borg terminology, a collection of machines that form a unit of management within a data center.
Task: The basic unit of work in Borg, representing a specific process or part of an application.
Borg Master: The central controller in a Borg cell, responsible for managing client requests and maintaining the cell's state.
Borglet: A local Borg agent present on each machine in a cell, responsible for starting, stopping, and managing tasks.
Scheduler: A component in Borg that determines which tasks can be admitted and assigns them to machines.
Container: A lightweight, isolated environment in which tasks run, providing resource isolation and management.
Resource reclamation: The process of dynamically reallocating resources from lower-priority tasks to higher-priority ones when needed.
Disaggregation: A design trend in data centers where different types of resources (compute, memory, storage) are separated and can be scaled independently.
Kubernetes: An open-source container orchestration system inspired by Borg, widely used for managing containerized applications in modern data centers.
Review Questions
Explain the Split-kernel design, what are the goals it aims to achieve?
The split-kernel design aims to create an operating system architecture that supports hardware resource disaggregation by separating traditional OS functionality into distinct components that each manage a specific type of resource.
The primary goals of the split-kernel design are:
-
To enable effective management of disaggregated hardware resources in datacenters, where different types of resources (compute, memory, storage) can be physically separated and independently scaled.
-
To provide a more flexible resource allocation model that breaks away from the monolithic server approach, allowing resources to be allocated independently based on application needs.
-
To improve resource utilization by enabling fine-grained allocation across disaggregated components rather than allocating entire machines.
-
To increase system resilience by designing components to detect and recover from failures across the disaggregated infrastructure.
-
To maintain performance while working across non-coherent network fabrics connecting the disaggregated resources.
The split-kernel approach fundamentally differs from traditional monolithic kernels and microkernels by completely decoupling the management of different hardware resources and distributing these functions across the network.
Explain the design and implementation of LegoOS, and whether/how does it meet the split-kernel design goals?
LegoOS is a practical implementation of the split-kernel design concept. It disaggregates the traditional operating system into distributed monitors, each responsible for managing a specific type of hardware resource.
Design and Implementation of LegoOS:
-
Architecture: LegoOS divides OS functionality into separate monitors that run on different hardware components:
- Process monitors for CPU resources
- Memory monitors for memory resources
- Storage monitors for storage resources
-
Process Management: Process monitors manage CPU scheduling, process creation, and execution, providing a Linux-compatible process abstraction.
-
Memory Management: Memory monitors implement a distributed virtual memory system that presents a unified virtual memory space to applications while physically spanning multiple machines.
-
Communication Model: Components communicate via network messages over a non-coherent fabric, with no assumption of cache coherency between components.
-
Extended Cache (X-Cache): LegoOS introduces an extended cache on compute nodes to mitigate the performance impact of accessing remote memory, implementing this as a software-managed cache in DRAM.
-
Implementation Base: The prototype was built by modifying Linux kernel modules, leveraging existing components while implementing the split-kernel architecture.
How LegoOS meets the split-kernel design goals:
-
Resource Disaggregation Support: LegoOS successfully manages physically disaggregated hardware, allowing independent scaling of compute, memory, and storage resources.
-
Flexible Resource Allocation: It enables applications to use memory from one pool and compute from another, breaking the traditional server-based allocation model.
-
Improved Resource Utilization: As demonstrated in their TensorFlow experiment, LegoOS shows only 30-70% slowdown compared to unlimited local memory when using disaggregated memory, significantly outperforming other approaches when local memory is constrained.
-
Failure Resilience: LegoOS includes failure detection mechanisms where monitors can identify failures in other components and trigger recovery actions.
-
Performance Across Non-coherent Networks: Through the use of the extended cache and specialized RPC mechanisms, LegoOS mitigates the latency impact of network communication between disaggregated components.
The implementation demonstrates that a split-kernel approach is viable, though with some performance trade-offs compared to traditional systems. The prototype achieved these goals while maintaining backward compatibility with Linux applications.
Explain the result on the performance comparison of LegoOS vs. Linux vs. Infiniswap.
The lecture discusses performance comparison results between LegoOS, standard Linux, and Infiniswap when running a TensorFlow machine learning application using the CIFAR dataset. This experiment specifically tested how these systems perform under memory constraints.
Key findings from the comparison:
-
Baseline: The experiment used Linux with unlimited memory as the baseline for comparison, representing optimal performance.
-
Constrained Memory Scenarios: The systems were tested across different ratios of "extended cache" (local memory) to total memory needed, showing how performance changes as local memory becomes more limited.
-
Performance Results:
- When local memory was plentiful (right side of the graph), all solutions performed well, with minimal slowdown.
- As local memory became more constrained (left side of the graph), the performance differences became
dramatic:
- LegoOS: Showed only 30-70% slowdown compared to unlimited memory, even with severely limited local memory.
- Linux with SSD swap: Performed poorly under memory constraints, with much higher slowdowns.
- Linux with RAM disk: Also showed significant performance degradation.
- Infiniswap: Performed better than standard Linux solutions but still significantly worse than LegoOS.
-
Key Advantage: LegoOS's architecture, designed specifically for disaggregated resources, handled limited local memory much more gracefully than the other systems, which were built on the assumption of unified resources.
This result demonstrates that LegoOS's split-kernel design provides significant advantages in environments with disaggregated memory resources, particularly when applications need more memory than is locally available. The experiment validates that a purpose-built OS for disaggregated hardware can outperform traditional OS designs with add-on remote memory solutions like Infiniswap.
Comment on the complexity of resource management in datacenter systems, where are some of the contributing factors?
Resource management in datacenter systems is extraordinarily complex due to multiple interacting factors:
-
Scale and Heterogeneity:
- Modern datacenters contain thousands to tens of thousands of machines
- Wide variety of hardware components (CPUs, GPUs, TPUs, specialized accelerators)
- Multiple generations of hardware coexisting in the same datacenter
- Different memory and storage technologies with varying performance characteristics
-
Workload Diversity:
- Mix of long-running services and batch jobs with different requirements
- Varying levels of priority and latency sensitivity among applications
- Multi-tenancy with different customers having different SLAs
- Thousands of tasks from a single application needing coordination
-
Resource Allocation Challenges:
- Need to map application requirements to specific hardware capabilities
- Balancing high utilization against application performance
- Managing resource fragmentation across the datacenter
- Over-commitment and reclamation of unused resources
- Providing performance isolation between workloads
-
Reliability Requirements:
- Need to handle machine failures gracefully
- Avoiding correlated failures that could affect entire services
- Maintaining service availability during maintenance and upgrades
- Task rescheduling and fail-over mechanisms
-
Optimizing for Different Metrics:
- Latency for user-facing services
- Throughput for batch processing
- Cost efficiency across the entire infrastructure
- Energy consumption and carbon footprint
-
System Complexity:
- Distributed systems spanning multiple buildings or regions
- Complex networks with different topologies and performance characteristics
- Coordination needed across thousands of components
- Cascading effects where local decisions impact global performance
-
Emerging Technologies:
- Resource disaggregation changing traditional machine boundaries
- New interconnect technologies requiring specialized management
- Persistent memory blurring the line between memory and storage
- Software-defined infrastructure adding new abstraction layers
The papers highlight how datacenter resource management has evolved from simpler cluster management to sophisticated orchestration systems dealing with these complexities, requiring hierarchical designs, specialized policies, and new OS architectures like split-kernel designs to address emerging hardware trends.
The design of Borg, based on Borgmaster, scheduler, and Borglet, and the manner Borg distributes functionality across these components, helps it to achieve greater scalability and efficiency. Explain how the design, mechanisms and optimizations in each of these components contribute to these goals.
The Borg system's architecture with Borgmaster, scheduler, and Borglet components incorporates several design choices and optimizations that contribute to its scalability and efficiency:
Borgmaster:
- Replicated Design: The Borgmaster is replicated five times for high availability, with one elected leader handling state mutations.
- State Management: Uses Paxos for distributed, consistent state storage across replicas.
- Link Shards: Borgmaster divides communication with Borglets among its replicas, so each replica handles a subset of machines, distributing the communication load.
- Separation of Concerns: The scheduler was split into a separate process to operate in parallel with other Borgmaster functions.
- Asynchronous Operation: Uses separate threads for read-only RPCs and Borglet communication, improving response times.
- Checkpointing: Maintains state checkpoints that enable debugging, restoration, and offline simulation (Fauxmaster).
Scheduler:
- Feasibility Checking and Scoring: Two-phase process first filters feasible machines, then scores them efficiently.
- Score Caching: Avoids recalculating scores until machine or task properties change.
- Equivalence Classes: Groups tasks with identical requirements to avoid redundant scheduling calculations.
- Relaxed Randomization: Examines machines in random order until finding "enough" feasible machines, reducing scoring overhead.
- Parallelization: Operates as a separate process from the Borgmaster, enabling concurrent operations.
- Optimistic Concurrency: Makes recommendations to the Borgmaster, which can accept or reject them based on current state, similar to the Omega approach.
Borglet:
- Local Resource Management: Manages resources on individual machines, including manipulating cgroups and local OS settings.
- State Reporting: Reports machine state to the Borgmaster to inform scheduling decisions.
- Polling Model: Borgmaster polls Borglets for updates, giving the central controller more power over communication rate.
- Failure Handling: Continues operation even if disconnected from Borgmaster, maintaining running tasks during master failures.
- Automatic Recovery: Can kill duplicate tasks if they've been rescheduled elsewhere during network partitions.
Cross-Component Optimizations:
- Communication Efficiency: Link shards aggregate and compress Borglet information, reducing the update load on the elected master.
- Failure Domain Awareness: The system spreads tasks across failure domains to improve resilience.
- Resource Reclamation: Uses a sophisticated system to reclaim unused resources while protecting high-priority workloads.
- Priority Bands: Uses clear non-overlapping priority bands (production, batch, etc.) to manage preemption and resource allocation.
- Cell Organization: Divides the infrastructure into cells of manageable size, each with independent Borg instances.
These design decisions collectively enable Borg to scale to tens of thousands of machines while maintaining high reliability and efficiency. The distribution of functionality across components, efficient communication patterns, and various optimizations for common operations allow Borg to handle the complexity of Google's diverse workloads with minimal human intervention.
Explain the select result from the Borg paper.
The Borg paper presents several key experimental results, with one of the most significant being the efficiency gains from resource sharing and resource pooling. This result demonstrates why Google chose to run both production and non-production workloads on the same machines.
The experiment specifically examined:
-
Overhead from Segregation: The paper investigated how many additional machines would be required if production and non-production workloads were run on separate, dedicated clusters rather than combined.
-
Methodology: The researchers took production workload traces from real Google clusters and replayed them in both a shared configuration (production and non-production jobs on the same machines) and a segregated configuration (separate machines for each type).
-
Results: The experiment found that segregating workloads would require approximately 20-30% more machines in the median case across 15 representative cells, with some cells requiring up to 50% more machines.
-
Root Cause: This substantial efficiency gain comes from complementary resource usage patterns:
- Production jobs typically reserve resources to handle peak loads but do not continuously use all reserved resources
- The Borg scheduler reclaims these temporarily unused resources to run lower-priority batch jobs
- When production jobs need their full allocation, batch jobs can be quickly preempted
-
Impact: At Google's scale, even small improvements in efficiency translate to significant cost savings. The 20-30% efficiency improvement represents millions of dollars in hardware costs, as well as associated power, cooling, and datacenter space savings.
This result validates one of Borg's fundamental design decisions: to create a unified scheduling system that can handle diverse workloads with different priorities and resource needs, rather than creating separate clusters for different types of jobs. The paper demonstrates that workload consolidation, coupled with appropriate preemption and resource reclamation policies, provides substantial efficiency benefits in large-scale datacenter environments.